논문: https://ieeexplore.ieee.org/document/9063543
저자: Jiangxin Yang , Guizhong Fu , Wenbin Zhu , Yanlong Cao , Yanpeng Cao , Member, IEEE, and Michael Ying Yang, Senior Member, IEEE
인용: Yang, Jiangxin, et al. "A deep learning-based surface defect inspection system using multiscale and channel-compressed features." IEEE transactions on instrumentation and measurement 69.10 (2020): 8032-8042.
0. 초록 (Abstract)
기계 학습 중 vision을 기반으로 한 표면 검사에서, 결함은 배경과 유사하지만 다른 국소적 이상체 (local anomaly)로 간주한다. 해당 이유로 결함은 일반적인 분류 작업보다 어렵다. 결함 분류 작업을 어렵게 만드는 다른 요소는 산업 제품이 일반적으로 복잡하게 구성되어 있다. 이런 복잡한 요소들을 structural interference(SI)라고 부르며, 그 예로 hallow regions, welding joints, or rivet holes 등이 존재한다. 추가로 결함은 종류가 다양하며 그 크기도 제각각이다.
저자는 이러한 문제를 해결하기 위해 새로운 모델을 제안한다. 모델은 수용 영역(receptive field)을 늘리기 위해 다양한 크기의 커널들을 가진 convolutional layer들을 통합한다. 추가로 새롭게 추가된 convolutional layer들의 parameter size를 압축하였다. 그 이유는 훈련데이터의 샘플 수가 적기에 결함을 판단하는 특징을 잘 학습하기 위해서이다.
1. 서론 (Introduction)
강철, 플라스틱, 돌 등과 같은 원재료 (raw materials)의 표면 결함은 완제품의 질을 낮춘다. 그렇기에 생산 공정에서 표면 결함 검출은 중요한 역할을 가진다. 사람이 결함 검출을 하면 주관적이고 고된 일이므로, 저자는 객관적이고 자동화된 기계 학습 vision 검사를 개발하였다.
최근 CNN 모델이 객체 인식, 이미지 분할, 얼굴 인식 등 컴퓨터 비전에서 다양하게 사용된다. 저자는 결함 검출을 위해 CNN 모델을 이용한다. 모델은 세 단계로 나누어진다. 첫째, 관심 영역 (region of interest, ROI) 추출, 둘째, 결함 분류, 셋째, 결함 위치 파악이다. 실제 사진에서 배경을 제외한 관심 영역을 추출하고, 이를 patch 단위로 분리하여 CNN 모델에서 결함을 분류한다. 결함으로 분류된 패치들을 통해 결함 위치를 파악한다.
논문의 기여도는 아래와 같다.
- 새로운 표면 결함 데이터셋을 구성하였다. 데이터셋의 이름 USB-SD이며 Universal Serial Bus (USB) connectors 이미지이다. 이는 빛을 반사하는 stainless steel 재질이며, hallow areas, welding joints, and rivet holes 와 같은 복잡한 구조를 가지고 있다. 또한 결함의 사이즈는 종류마다 다르다.
- 모델은 SqueezeNet에 다양한 convolutional layer들을 추가하였다. Convolutional layer는 다양한 커널 사이즈를 가지고 있어, 더 큰 수용 영역(RF)을 가지므로 여러 크기의 feature를 얻을 수 있다.
2. 이미지 습득 시스템 조건 및 USB-SD 데이터셋 (Image Acquisition System Configuration and USB-SD Data Set)
이미지 습득 시스템은 아래 그림1 을 참고한다.
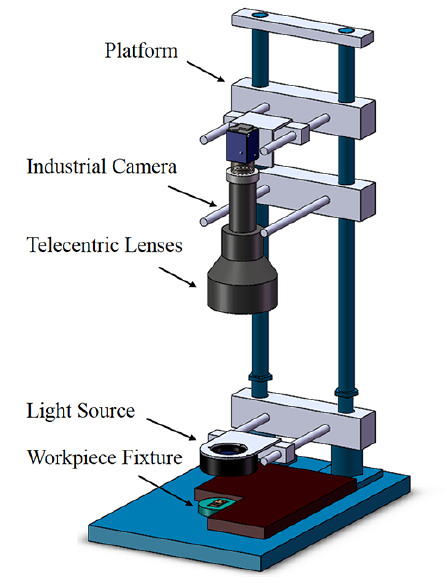
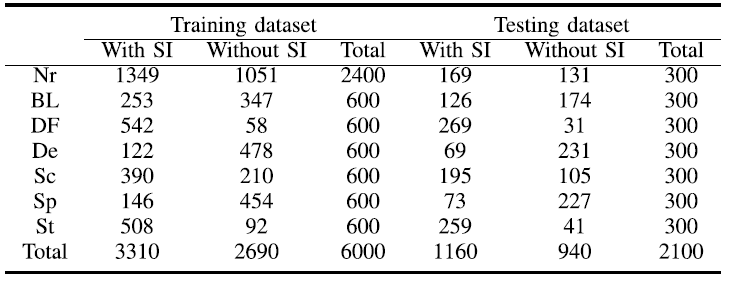
데이터 셋은 200px*200px 패치 이미지의 집합이다. 레이블은 사람이 직접 정의한다. USB-SD 데이터셋은 grayscale 이미지 8,100장이다. 클래스는 정상 클래스와 6개의 결함 클래스이다. 결함 클래스는 BrightLine, Deformation, Dent, Scratch, Spot, Stain이다. 훈련데이터는 6,000장이며, 정상이미지가 2,400장, 결함이미지는 각 600장씩 총 3,600장이다. 생산공정에서 결함 제품이 발생할 확률은 낮기에 정상 클래스의 샘플 수가 많다. 테스트 데이터는 총 7개의 클래스에 동일하게 300장씩 존재하여 총 2,100장이다. 훈련데이터와 테스트데이터는 각각 다른 USB 제품으로부터 얻었다. 표1 을 참고하여 데이터셋을 확인할 수 있다. SI의 예시는 아래 그림2 와 같다. 또한 결함의 크기는 종류별로 다르다. 아래 그림 3을 참고할 수 있다.


3. 제안된 방법 (Proposed Method)
모델의 작동 방식은 그림4 와 같다.
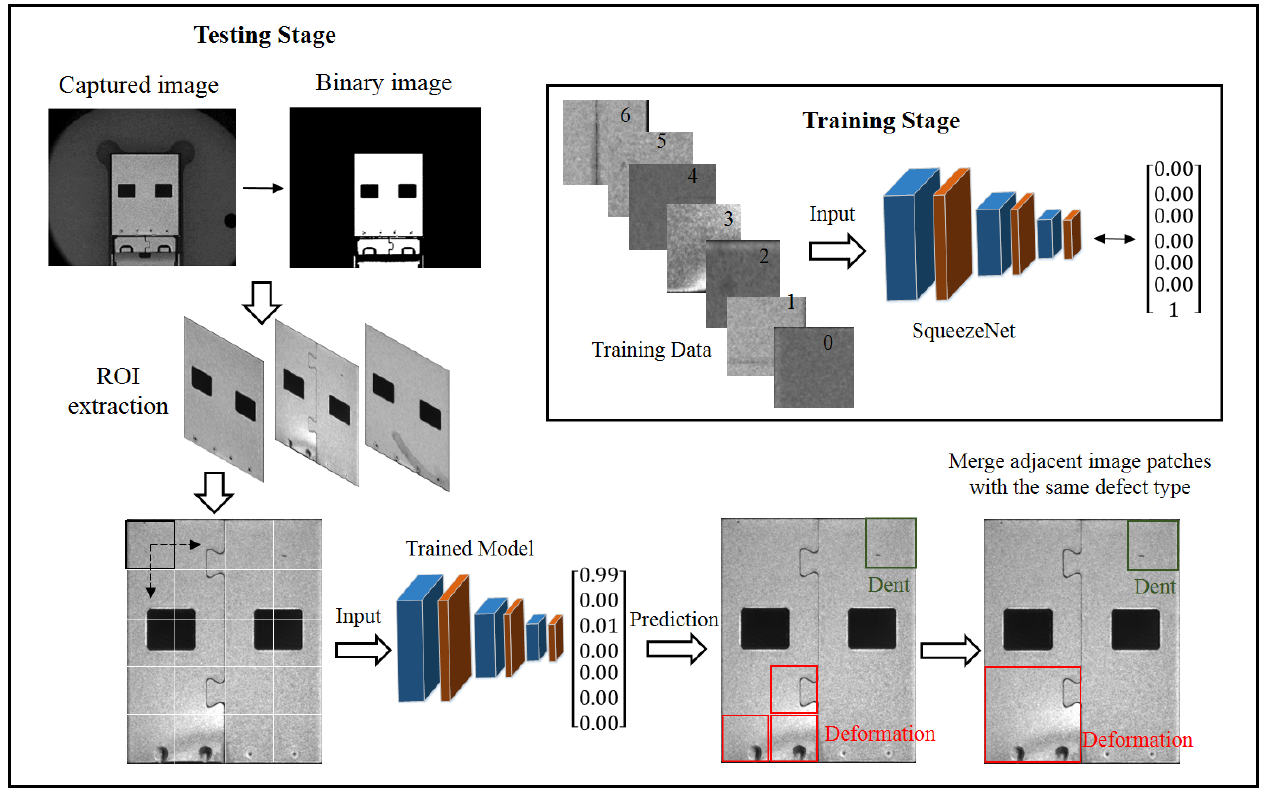
모델의 작동 순서는 다음과 같다.
- Full-size 이미지에서 ROI를 추출하기 위해 OSTU 알고리즘을 사용한다.
- ROI 이미지는 균등한 크기로 패치화를 진행하여 CNN 모델에서 결함 유무를 판단한다. CNN모델은 ImageNet-1k로 사전 훈련된 SqueezeNet을 사용하며 해당 데이터셋으로 전이학습을 실시한다.
- 인접하면서 동시에 같은 결함 클래스를 가진 패치들은 결함 위치(location map)로 정의한다.
A. ROI Extraction
제품에서 target 이미지 (ROI 이미지)를 습득하기 위해 OSTU를 사용한다. 이를 통해 얻은 templete을 사용하여 각 Full-size 이미지들로부터 ROI (800px*1000px)를 추출할 수 있다. 추출된 ROI 이미지는 균등한 크기의 패치 (200px*200px)로 자른다. 그리고 각 패치는 클래스를 분류하기 위해 CNN 모델에 입력으로 들어간다.
B. Surface Defect Classification
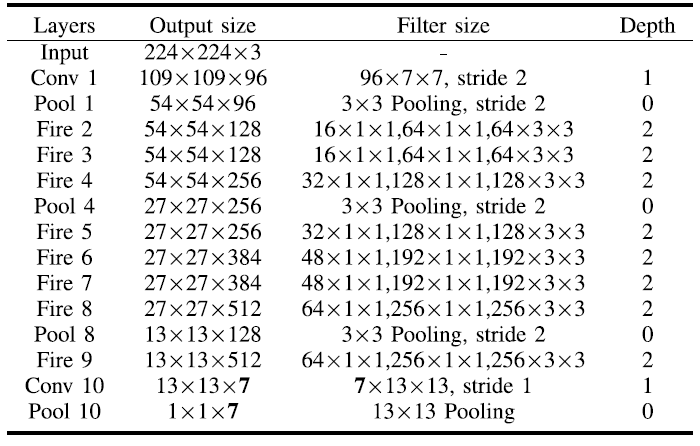
저자가 제안한 모델은 pretrained SqueezeNet (그림5)을 backbone으로 사용한다.

다만 결함 분류 클래스는 7개이므로, 마지막 Convolutional layer의 출력을 1000에서 7로 변경한다. 그리고 full connected layer를 대신하기 위해 global average pooling (GAP)을 이용한다. 세부 정보는 표2 와 같다.
손실함수는 수식1 과 같이 Cross-entropy loss를 사용한다.
\begin{align*}
& \mathcal{L} = - \sum_{k=1}^{7} t_k \log \Pr(y = k),
\tag{1}
\end{align*}
여기서 입력 이미지의 레이블이 k이면 $t_k=1$이고, 그렇지 않으면 $t_k=0$이다. $\Pr(y=k) \in [0,1]$은 confidence score이며, softmax를 사용하여 계산한다. 아래 수식2 와 같다.
\begin{align*}
& \Pr(y = k) = \frac{e^{G_k}}{\sum_{j=1}^{7} e^{G_j}},
\tag{2}
\end{align*}
여기서 $G_k$는 $k$번째 GAP layer의 출력값이다. 이는 $k$번째 클래스의 예측값이다.
추가로 결함 분류 작업에서 다양한 수용 영역 (RF)을 위해 모델의 마지막 특징 추출기 (Fire9)에 그림6 과 같이 MRF 모듈을 추가한다. 추가된 모듈은 총 3가지로 MRF-a ($1 \times 1$), MRF-b ($3 \times 3$), MRF-c ($5 \times 5$) 이들은 각각 127 (Fire9 이후), 159, 191의 RF를 가진다. RF를 계산하는 방법은 아래와 같다.
\begin{align*}
& R_i = R_{i-1} + (k_i - 1) \times \prod_{i=1}^{i} s_i,
\tag{3}
\end{align*}

(역자 주: Table 2 에서는 Conv 10 다음에 Pool 10이나 MRF 개선 구조에서는 Pool 10 다음에 Conv 10 이므로 최종 모델 구조는 후자 방식을 취함)
4. 실험 세부정보 (Implementation Details)
배치 사이즈:32, epoch: 2000, lr: 0.001 w/ polynomial formula, optimizer: SGD w/ momentum:0.9, weight decay: 0.0002, GPU: NVIDIA TITAN X GPU (12-GB memory)
5. 성능 분석
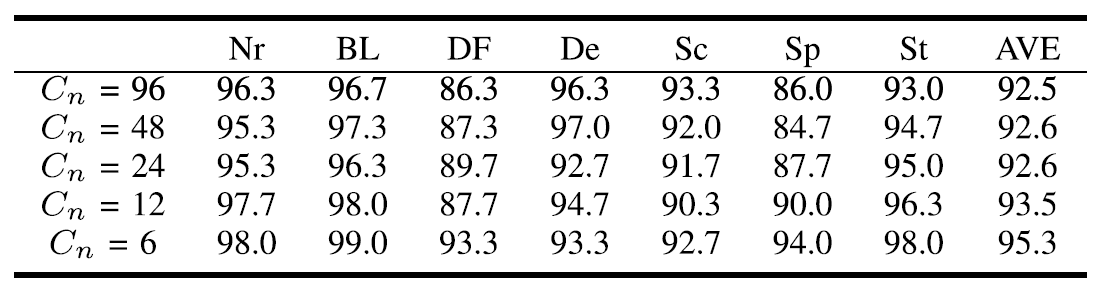
MRF 추가 유무에 대한 성능 분석 (Table 3)과 $C_n$을 96부터 6까지 줄인 경우의 성능 분석 (Table 4)

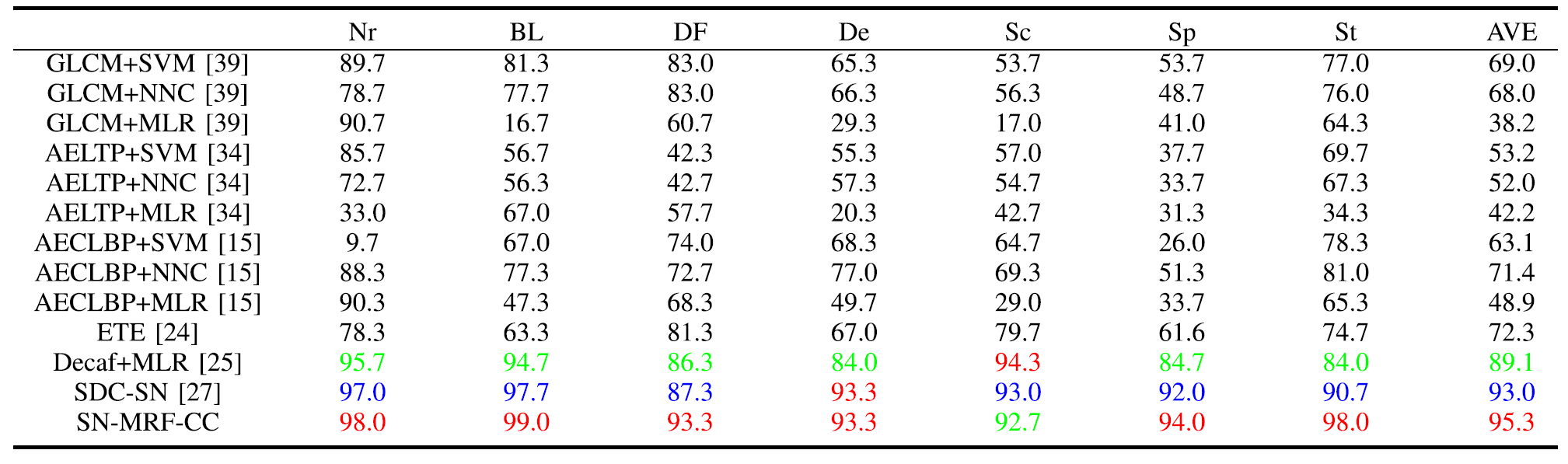
다양한 모델들과의 성능 비교 분석 (Table 5)
6. Pytorch 코드
1. Pre-trained SqueezeNet on ImageNet-1K
import torch.nn as nn
import torchvision.models as models
class SqueezeNet(nn.Module):
def __init__(self):
super(SqueezeNet, self).__init__()
# squeezenet1_0 model and pre-trained weights with ImageNet
squeezenet1_0 = models.squeezenet1_0(weights=models.SqueezeNet1_0_Weights.DEFAULT)
# features: no use fully connected layer of SqueezeNet
self.features = nn.Sequential(*list(squeezenet1_0.features.children()))
def forward(self, x):
x = self.features(x) # Start: (batch_size, 3, 100, 100)
return x
2. SN_MRF_CC
import torch
import torch.nn as nn
from model import SqueezeNet
class SN_MRF_CC(nn.Module):
def __init__(self, num_classes=7, Cn=6):
super().__init__()
self.squeezenet = SqueezeNet()
self.Cn = Cn
self.MRF_a = nn.Sequential(nn.Conv2d(512, self.Cn, kernel_size=1, padding=0), nn.ReLU())
self.MRF_b = nn.Sequential(nn.Conv2d(512, self.Cn, kernel_size=3, padding=1), nn.ReLU())
self.MRF_c = nn.Sequential(nn.Conv2d(512, self.Cn, kernel_size=5, padding=2), nn.ReLU())
# Short connection + fusion → Pool10
self.pool10 = nn.AdaptiveAvgPool2d((1, 1)) # [B, 3*Cn, 1, 1]
self.conv10 = nn.Conv2d(3 * self.Cn, num_classes, kernel_size=1)
self.short_conv = nn.Conv2d(512, 3 * self.Cn, kernel_size=1)
def forward(self, images):
features = self.squeezenet(images) # output: [B, 512, H, W] (Fire9/concat)
# 2. MRF branches
out_a = self.MRF_a(features) # [B, Cn, H, W]
out_b = self.MRF_b(features) # [B, Cn, H, W]
out_c = self.MRF_c(features) # [B, Cn, H, W]
# 3. Concatenate multi-scale features
fused = torch.cat([out_a, out_b, out_c], dim=1) # [B, 3*Cn, H, W]
# 4. Short connection: Fire9 output을 pooled에 더함 (채널 수 맞춰야 함)
shortcut = self.short_conv(features) # [B, 3*Cn, H, W]
residual = fused + shortcut # [B, 3*Cn, H, W]
# 5. Pooling & classification
pooled = self.pool10(residual) # [B, 3*Cn, 1, 1]
logits = self.conv10(pooled).squeeze(-1).squeeze(-1) # [B, num_classes]
return logits