아래 글은 OpenCV 사에서 제공하는 Vision Language Model Bootcamp 에 대한 교육 내용을 정리하였습니다. 다만 저작권은 OpenCV university에 있으므로 교육 자료 및 코드는 공유가 불가능합니다. 어떤 내용을 교육하는지 가볍게 살펴봐주세요! :)
Vision Language Model Bootcamp: Link <- 내용은 무료이니 추천합니다!
코스는 2시간으로 CLIP과 Qwen2.5-VL 에 대한 이론 및 실습 (colab)으로 구성되었다.
CLIP에 대해서는 이전에 다룬 적이 있기에 여기서는 생략한다. (CLIP 포스팅: Link)
그럼 Qwen2.5VL에 대해 이야기해보자.
1. Qwen2.5-VL
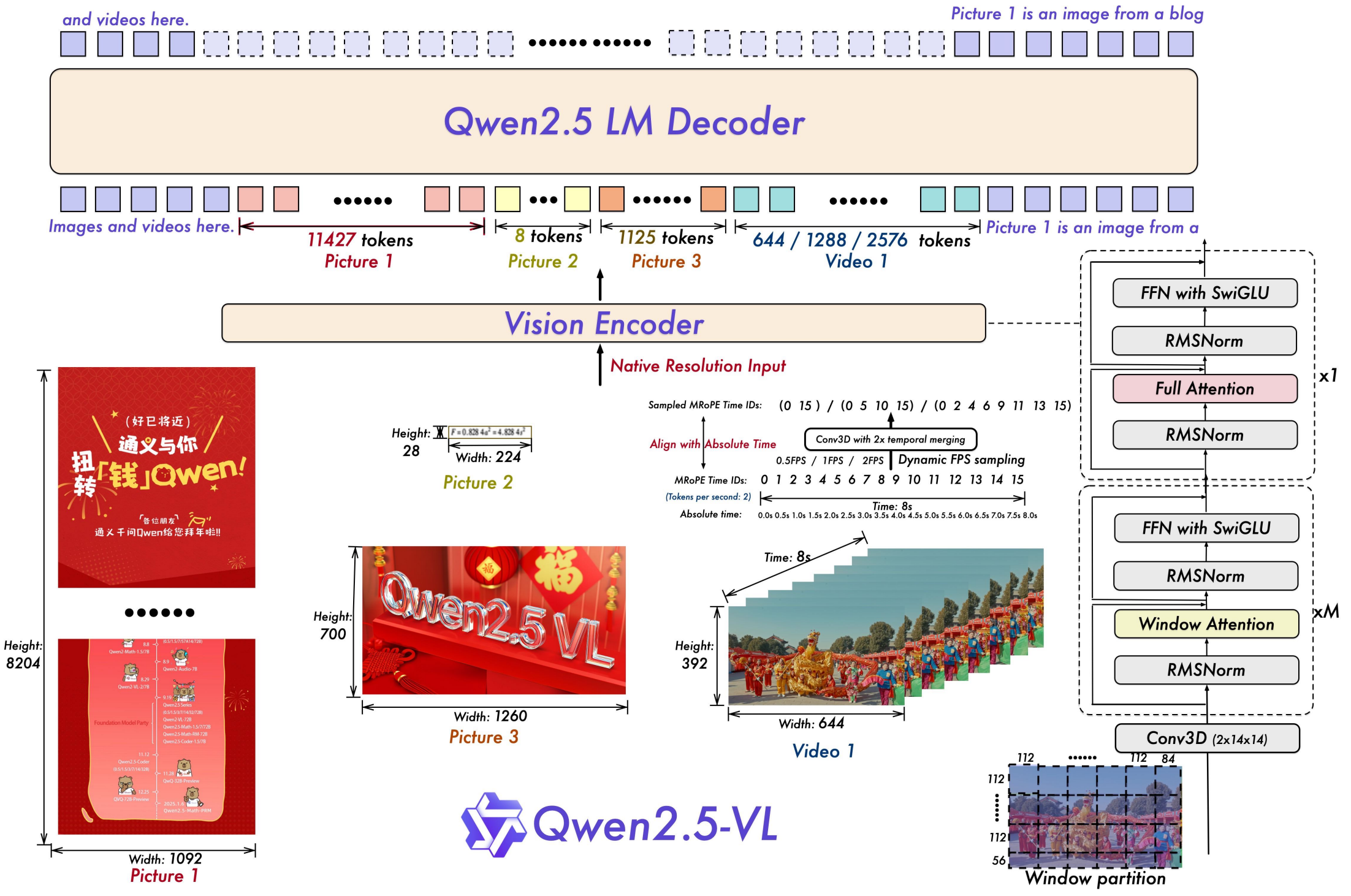
Qwen2.5-VL [1] 은 Qwen vision language 계열 모델로, vision encoder는 ViT를, LLM (decoder-only)으로는 Qwen2.5를 사용한다. arXiv 공개일자는 25년 2월 19일이다.
2. Image Captioning
실습은 Colab 환경에서 진행된다. Qwen2.5-VL은 Hugging Face [2] 에서 모델을 다운받을 수 있다. 구체적으로 사용한 모델은 Qwen2.5-VL의 3B 크기 + instruct (대화 가능) 모델이다. 실습에 사용한 이미지도 Unsplash [3]로 무료 사용이 가능하다.

프롬프트는 다음과 같다.
msgs = [
{
"role": "user",
"content": [
{"type": "image", "image": img},
{"type": "text", "text": "Describe this image."}
],
}
]Qwen2.5-VL을 통해 나온 캡션은 아래와 같다.
Caption: The image depicts a serene and picturesque scene of a white dog sitting on a stone pathway near a stunning lake. The lake has crystal-clear turquoise water that reflects the surrounding landscape, including the mountains in the background. The mountains are covered with lush greenery, and the sky above is partly cloudy, adding to the tranquil atmosphere.
3. Object Detection & Spatial Reasoning
실습 환경과 모델은 위와 동일하다. 다만 3B 모델 대신, 7B 모델을 사용한다. 둘 다 상관없다. 만약 실습을 위한다면 두 번 다운받지 말고, 이전 3B를 재활용하길 추천한다. 실습에 사용한 이미지 [4]는 아래와 같다.

모델에 해당 이미지와 다음과 같은 프롬프트를 제안한다.
msgs = [
{
"role": "system",
"content": [
{
"type": "text",
"text": (
"You are an object detector. The format of your output should be a valid JSON object "
"{'bbox_2d': [x1, y1, x2, y2], 'label': 'class'} where class is the name of the class you are detecting."
)
}
],
},
{
"role": "user",
"content": [
{"type": "image", "image": img},
{
"type": "text",
"text": "Outline the position of elephants"
}
],
}
]이전 섹션 (Image Captioning)과 다른 점이라면 role에 "system" 이 추가되었다. 즉 모델에게 object detector 역할을 부탁하는 것이다. 실행 결과는 다음과 같다.

추가로, 위 내용에서는 안 나왔지만, 두 번째 프롬프트의 text에서 단순 elephants가 아닌 mama elephant (e.g. Outline the position of mama elephant)와 같이 의미론적인 질문을 하여도 오른쪽 큰 코끼리를 탐지하는 것을 확인할 수 있다. 즉, 기존 OD 비전 모델과 다르게, LLM이 함께 하기에 의미론적인 추론이 가능하다. 이는 엄청난 것이다! AI가 점점 인간처럼 사고하고 행동한다는 것이다.
마무리를 하며...
전체적으로 유익하고 재미있는 수업이다. 하지만 bootcamp와 다르게 최소한 딥러닝 모델에 대한 경험이 필요하다. 글쓴이의 경우, 인공지능 전공으로 2년간 석사과정 (한달 뒤 석사 디펜스)을 통해 얻은 지식으로 별다른 무리 없이 이해했지만, 딥러닝을 시작한 사람에게는 Transformer의 개념과 같이 최신 모델의 기반이 되는 내용을 사전 숙지해야 도움이 되지 않을까 싶다.
4. References
[1] Bai, Shuai, et al. "Qwen2. 5-vl technical report." arXiv preprint arXiv:2502.13923 (2025).
[2] https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct
[3] https://images.unsplash.com/photo-1504208434309-cb69f4fe52b0?w=700
[4] https://learnopencv.com/wp-content/uploads/2025/06/elephants.jpg
{kind=link}
'Deep learning > Computer Vision' 카테고리의 다른 글
| [컴퓨터비전] 기초부터 시작하는 CLIP (Pytorch 구현) (1) | 2025.06.26 |
|---|---|
| [컴퓨터비전] 기초부터 시작하는 ViT (Pytorch 구현) (1) | 2025.06.23 |
| [컴퓨터비전] 데이터 증강 종류 및 코드 (Pytorch, Albumentations, Imgaug) (1) | 2024.12.06 |
| [컴퓨터비전] Cityscapes annotation을 COCO (.json)로 변경하는 방법 (2) | 2024.09.19 |
| [컴퓨터비전] KITTI dataset label (.txt) 파일을 PASCAL VOC label (.xml)로 변경하는 방법 (0) | 2024.09.19 |